I’ve recently been involved in some APEX development.
One of the application form had a bunch of input items whose visibility and mandatory aspects depend on the record type, and the business role of the current user.
This situation is typically handled with dynamic actions (DAs), and custom classes on items to minimize the number of DAs.
However, for this task, I chose to build an external item property matrix (in the form of an Excel file) to further minimize the amount of declarative settings in APEX.
Here’s a very simplified example of such a matrix :
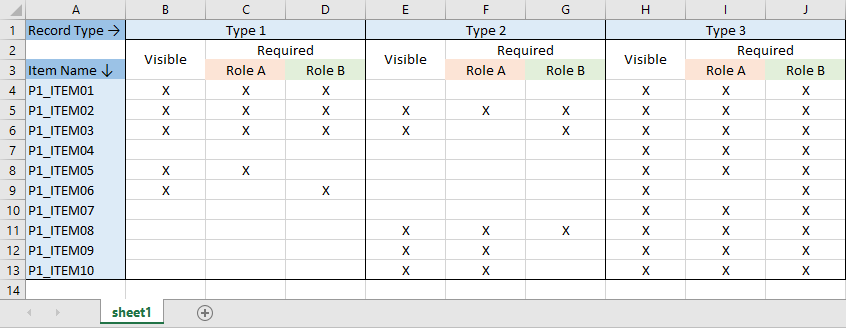
There are three record types (Type 1, Type 2, Type 3), two user roles (Role A, Role B) and ten items.
For instance, P1_ITEM01 is visible when the record type is ‘Type 1’ or ‘Type 3’, and is required when the current user possesses either ‘Role A’ or ‘Role B’.
The idea is now to transform that into a readily-usable format so that a single DA will suffice to set all items properties depending on the record type and user role.
Since I’ll be using JavaScript, I naturally chose a JSON format :
{
"T1": {
"hidden": ["P1_ITEM04","P1_ITEM07","P1_ITEM08","P1_ITEM09","P1_ITEM10"],
"required": {
"ROLE_A": ["P1_ITEM01","P1_ITEM02","P1_ITEM03","P1_ITEM05"],
"ROLE_B": ["P1_ITEM01","P1_ITEM02","P1_ITEM03","P1_ITEM06"]
}
},
"T2": {
"hidden": ["P1_ITEM01","P1_ITEM04","P1_ITEM05","P1_ITEM06","P1_ITEM07"],
"required": {
"ROLE_A": ["P1_ITEM02","P1_ITEM08","P1_ITEM09","P1_ITEM10"],
"ROLE_B": ["P1_ITEM02","P1_ITEM03","P1_ITEM08"]
}
},
"T3": {
"hidden": [],
"required": {
"ROLE_A": ["P1_ITEM01","P1_ITEM02","P1_ITEM03","P1_ITEM04","P1_ITEM05","P1_ITEM07","P1_ITEM08","P1_ITEM09","P1_ITEM10"],
"ROLE_B": ["P1_ITEM01","P1_ITEM02","P1_ITEM03","P1_ITEM04","P1_ITEM05","P1_ITEM06","P1_ITEM07","P1_ITEM08","P1_ITEM09","P1_ITEM10"]
}
}
}
1- Generating the JSON File
The transformation is carried out using a single SQL query over the Excel file :
with sheetdata as (
select *
from ExcelTable.getRows(
p_file => to_blob(bfilename('TEST_DIR', 'role-item-matrix.xlsx'))
, p_sheet => 'sheet1'
, p_cols => q'{
"ITEM" varchar2(30) column 'A'
, "T1_VISIBLE" varchar2(1) column 'B'
, "T1_REQUIRED_A" varchar2(1) column 'C'
, "T1_REQUIRED_B" varchar2(1) column 'D'
, "T2_VISIBLE" varchar2(1) column 'E'
, "T2_REQUIRED_A" varchar2(1) column 'F'
, "T2_REQUIRED_B" varchar2(1) column 'G'
, "T3_VISIBLE" varchar2(1) column 'H'
, "T3_REQUIRED_A" varchar2(1) column 'I'
, "T3_REQUIRED_B" varchar2(1) column 'J'
}'
, p_range => 'A4'
)
),
unpivoted as (
select *
from sheetdata
unpivot include nulls (
(visible, required_a, required_b)
for record_type in (
(t1_visible, t1_required_a, t1_required_b) as 'T1'
, (t2_visible, t2_required_a, t2_required_b) as 'T2'
, (t3_visible, t3_required_a, t3_required_b) as 'T3'
)
)
)
select json_serialize(
json_objectagg(
record_type value json_object(
'hidden' value json_arrayagg(case when visible is null then item end order by item)
, 'required' value json_object(
'ROLE_A' value json_arrayagg(case when required_a = 'X' then item end order by item)
, 'ROLE_B' value json_arrayagg(case when required_b = 'X' then item end order by item)
)
)
returning clob
)
returning clob pretty
) as json_content
from unpivoted
group by record_type
;
Let’s break down the query into smaller parts.
a- Reading the Excel file (“sheetdata” subquery)
I chose to use ExcelTable for this task :
select *
from ExcelTable.getRows(
p_file => to_blob(bfilename('TEST_DIR', 'role-item-matrix.xlsx'))
, p_sheet => 'sheet1'
, p_cols => q'{
"ITEM" varchar2(30) column 'A'
, "T1_VISIBLE" varchar2(1) column 'B'
, "T1_REQUIRED_A" varchar2(1) column 'C'
, "T1_REQUIRED_B" varchar2(1) column 'D'
, "T2_VISIBLE" varchar2(1) column 'E'
, "T2_REQUIRED_A" varchar2(1) column 'F'
, "T2_REQUIRED_B" varchar2(1) column 'G'
, "T3_VISIBLE" varchar2(1) column 'H'
, "T3_REQUIRED_A" varchar2(1) column 'I'
, "T3_REQUIRED_B" varchar2(1) column 'J'
}'
, p_range => 'A4'
)
;
ITEM T1_VISIBLE T1_REQUIRED_A T1_REQUIRED_B T2_VISIBLE T2_REQUIRED_A T2_REQUIRED_B T3_VISIBLE T3_REQUIRED_A T3_REQUIRED_B
------------------------------ ---------- ------------- ------------- ---------- ------------- ------------- ---------- ------------- -------------
P1_ITEM01 X X X X X X
P1_ITEM02 X X X X X X X X X
P1_ITEM03 X X X X X X X X
P1_ITEM04 X X X
P1_ITEM05 X X X X X
P1_ITEM06 X X X X
P1_ITEM07 X X X
P1_ITEM08 X X X X X X
P1_ITEM09 X X X X X
P1_ITEM10 X X X X X
Built-in API APEX_DATA_PARSER.PARSE would be another option here :
select col001 as ITEM
, col002 as T1_VISIBLE
, col003 as T1_REQUIRED_A
, col004 as T1_REQUIRED_B
, col005 as T2_VISIBLE
, col006 as T2_REQUIRED_A
, col007 as T2_REQUIRED_B
, col008 as T3_VISIBLE
, col009 as T3_REQUIRED_A
, col010 as T3_REQUIRED_B
from apex_data_parser.parse(
p_content => to_blob(bfilename('TEST_DIR', 'role-item-matrix.xlsx'))
, p_file_type => 1 -- c_file_type_xlsx
, p_skip_rows => 3
)
;
b- Unpivoting per record type (“unpivoted” subquery)
Here, each column triplet (VISIBLE, REQUIRED_A, REQUIRED_B) is unpivoted per record type :
select *
from sheetdata
unpivot include nulls (
(visible, required_a, required_b)
for record_type in (
(t1_visible, t1_required_a, t1_required_b) as 'T1'
, (t2_visible, t2_required_a, t2_required_b) as 'T2'
, (t3_visible, t3_required_a, t3_required_b) as 'T3'
)
)
ITEM RECORD_TYPE VISIBLE REQUIRED_A REQUIRED_B
------------------------------ ----------- ------- ---------- ----------
P1_ITEM01 T1 X X X
P1_ITEM01 T2
P1_ITEM01 T3 X X X
P1_ITEM02 T1 X X X
P1_ITEM02 T2 X X X
P1_ITEM02 T3 X X X
P1_ITEM03 T1 X X X
P1_ITEM03 T2 X X
P1_ITEM03 T3 X X X
P1_ITEM04 T1
P1_ITEM04 T2
P1_ITEM04 T3 X X X
P1_ITEM05 T1 X X
P1_ITEM05 T2
P1_ITEM05 T3 X X X
P1_ITEM06 T1 X X
P1_ITEM06 T2
P1_ITEM06 T3 X X
P1_ITEM07 T1
P1_ITEM07 T2
P1_ITEM07 T3 X X X
P1_ITEM08 T1
P1_ITEM08 T2 X X X
P1_ITEM08 T3 X X X
P1_ITEM09 T1
P1_ITEM09 T2 X X
P1_ITEM09 T3 X X X
P1_ITEM10 T1
P1_ITEM10 T2 X X
P1_ITEM10 T3 X X X
c- Main query
We’re almost there. The last step consists in generating the JSON file by aggregating lists of items by role and visibility (using JSON_ARRAYAGG), and then by record type (using JSON_OBJECTAGG) :
select json_serialize(
json_objectagg(
record_type value json_object(
'hidden' value json_arrayagg(case when visible is null then item end order by item)
, 'required' value json_object(
'ROLE_A' value json_arrayagg(case when required_a = 'X' then item end order by item)
, 'ROLE_B' value json_arrayagg(case when required_b = 'X' then item end order by item)
)
)
returning clob
)
returning clob pretty
) as json_content
from unpivoted
group by record_type
NB: I used JSON_SERIALIZE with pretty-print option for debugging purpose. It should not be used in a production environment.
2- Using the File in APEX
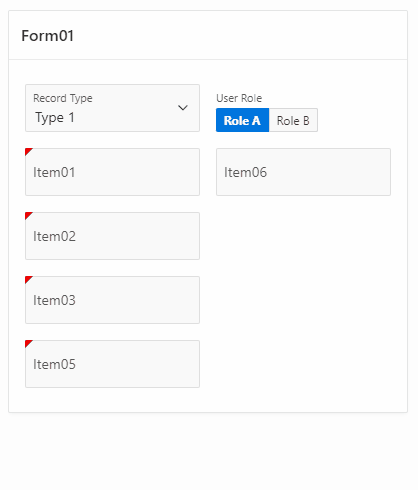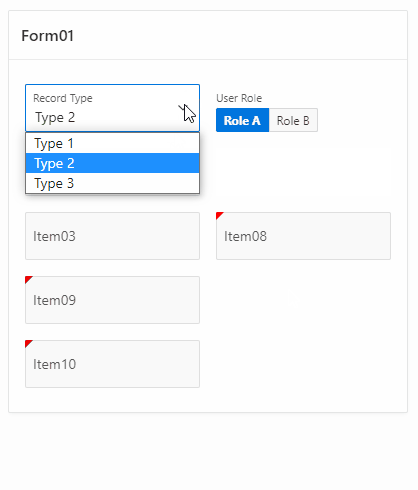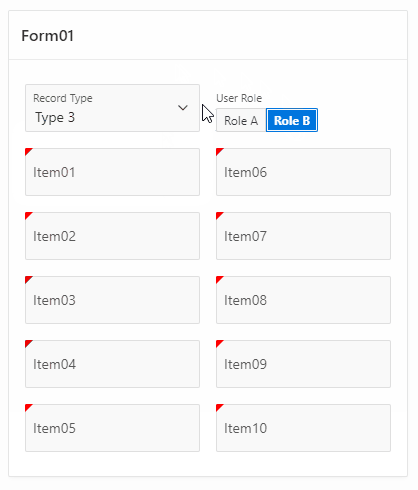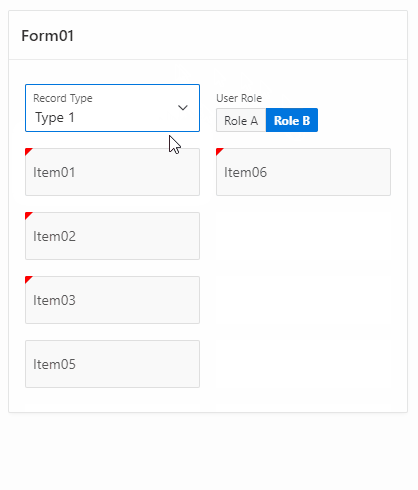
Here’s what the form region looks like without the rules applied :
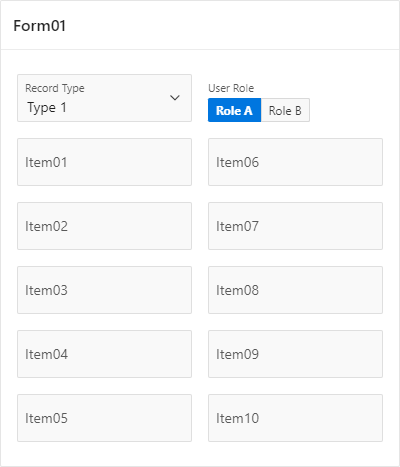
In my actual use case, “User Role” is an hidden application item. I’ve included it here with a selector for testing purpose.
“Record Type” item is a select list holding the aforementioned three display values : ‘Type 1’, ‘Type 2’, ‘Type 3’ (and their respective return values ‘T1’, ‘T2’ and ‘T3’).
In order to reference the matrix from APEX, the JSON file is uploaded as an application static file named “item-property-matrix.json”.
Next, we declare a global variable in the page “Function and Global Variable Declaration” section. This variable will hold the JSON content throughout the life of the page :
var itemPropertyMatrix;
Last step is to define an on-change DA on the “Record List” item (P1_RECORD_TYPE), with action “Execute JavaScript code” :
function setRequired(item, state) {
item.prop("required", state);
if (state) {
item.closest(".t-Form-fieldContainer").addClass("is-required");
} else {
item.closest(".t-Form-fieldContainer").removeClass("is-required");
}
}
function applyRules() {
const recordType = $v("P1_RECORD_TYPE");
const userRole = $v("P1_USER_ROLE");
//show currently hidden items
$(".recordtype-hidden").each(function(){
apex.item(this.id).show();
$(this).removeClass("recordtype-hidden");
});
itemPropertyMatrix[recordType].hidden.forEach(e => {
var item = apex.item(e);
item.hide();
item.node.classList.add("recordtype-hidden");
});
//remove required property from items
$(".recordtype-required").each(function(){
setRequired($(this), false);
$(this).removeClass("recordtype-required");
});
itemPropertyMatrix[recordType].required[userRole].forEach(e => {
var item = $("#" + e);
setRequired(item, true);
item.addClass("recordtype-required");
});
}
if (itemPropertyMatrix === undefined) {
fetch("#APP_IMAGES#item-property-matrix.json", {cache: "force-cache"})
.then(res => res.json())
.then(json => {
//console.log(json);
itemPropertyMatrix = json;
applyRules();
})
;
} else {
applyRules();
}
And here it is in live action :